Parse Document (Deprecated)
You can use the REST API to upload documents directly to DocumentPro. Once uploaded, documents are parsed automatically and available for export from the portal or using the API.
Guide to implementing API
API Endpoint
POST https://api.documentpro.ai/files/upload/{parser_id}
Query Parameters
You can customize the parsing process by adding the following query parameters to the API endpoint:
query_model: Specifies the AI model for parsing. Options aregpt-4o-miniorgpt-4o.page_ranges: Specifies which pages to parse (e.g., "1-3,5,7-9").use_ocr: Set totrueto enable OCR processing. It must be true if query_model is set togpt-3.5-turboor if using any OCR-related parameters.detect_layout: Set totrueto detect document layout (only applies ifuse_ocris true).detect_tables: Set totrueto detect tables (only applies ifuse_ocris true).
Document Segmentation
chunk_by_pages: An integer specifying how many pages to use in each segment for method 1 segmentation.rolling_window: An integer specifying the window size for method 2 segmentation.start_regex: A regex pattern to define where parsing should begin for method 3 segmentation (requiresuse_ocr=true).end_regex: A regex pattern to define where parsing should end for method 3 segmentation (requiresuse_ocr=true).split_regex: A regex pattern to split the document into sections for method 4 segmentation (requiresuse_ocr=true).use_all_matches: Set totrueto use all regex matches instead of just the first for methods 3 and 4 (requiresuse_ocr=true).
These parameters default to the values set in the parser if not specified in the API call. Page ranges do not apply to image files. If page ranges are not specified, all pages will be processed.
Example Implementation using Python
import requests
parser_id = "your_parser_id"
url = f"https://api.documentpro.ai/files/upload/{parser_id}"
# Add query parameters
params = {
"query_model": "gpt-4o",
"page_ranges": "1-3,5",
"use_ocr": "true",
"detect_layout": "true",
"detect_tables": "true",
"chunk_by_pages": "5",
"use_all_matches": "true"
}
payload = {}
files = [
('file', ('filename.pdf', open('filepath/filename.pdf', 'rb'), 'application/pdf'))
]
headers = {
'x-api-key': 'API_KEY'
}
response = requests.post(url, headers=headers, params=params, data=payload, files=files)
if response.status_code == 200:
result = response.json()
print(f"File uploaded successfully. Request ID: {result['request_id']}, Document ID: {result['document_id']}")
else:
print('Failed to upload file')
print(response.json())
Example Implementation using Node.js
const axios = require('axios');
const FormData = require('form-data');
const fs = require('fs');
const parserId = 'your_parser_id';
const url = `https://api.documentpro.ai/files/upload/${parserId}`;
const form = new FormData();
form.append('file', fs.createReadStream('filepath/filename.pdf'));
const params = {
query_model: 'gpt-4o',
page_ranges: '1-3,5',
use_ocr: 'true',
detect_layout: 'true',
detect_tables: 'true',
chunk_by_pages: '5',
use_all_matches: 'true'
};
axios.post(url, form, {
headers: {
...form.getHeaders(),
'x-api-key': 'API_KEY'
},
params: params
})
.then(response => {
console.log(`File uploaded successfully. Request ID: ${response.data.request_id}, Document ID: ${response.data.document_id}`);
})
.catch(error => {
console.error('Failed to upload file');
console.error(error.response.data);
});
The API can upload files up to 6MB in size.
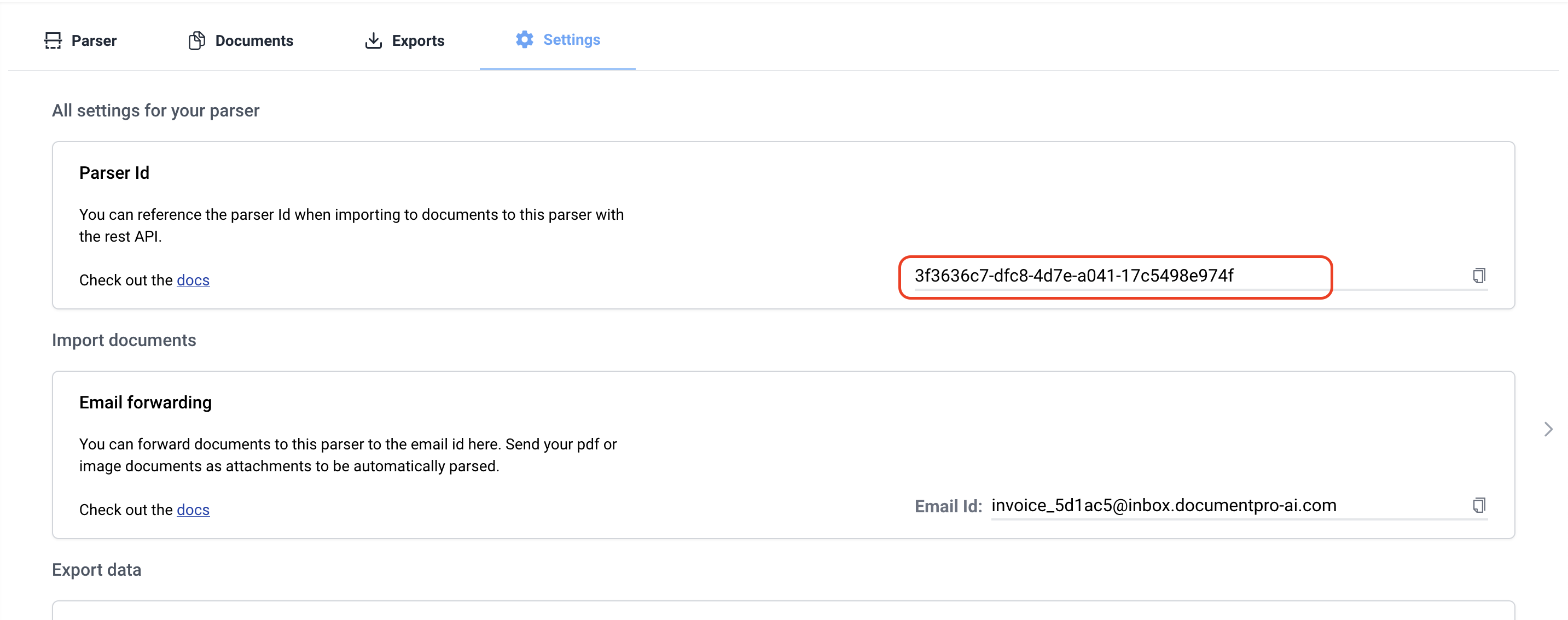
The parser_id is the unique identifier for a parser. You can copy it from the settings tab on a parser page.
Response body
A 200 status code will have the following body structure:
{
"success": true,
"request_id": "unique_identifier",
"document_id": "document_unique_identifier"
}
For status codes 400, 403, and 500, you will get the following response body:
{
"success": false,
"error": "error message"
}